Image generated by DALL-E (Prompt:Picture a time series forecast using LLM.)
はじめに
今年は、ChatGPTを始めとする生成AIの話題で持ち切りでした。自然言語系タスク中心に活用されているGPT(Generative Pre-trained Transformer)の時系列予測への応用に興味があり、予知保全への応用を考えてみたいと思います。いくつかの論文を元に、私の業務経験を踏まえて、考察したいと思います。
論文調査
ScholarAI というChatGPTのプラグインを使って、GPTやLLMの時系列予測へ応用についての論文を調べました。このプラグインは、「〇〇に関する論文の要約を教えてください。」と言うプロンプトを投げると、論文タイトル、要約、リンクを提示してくれるという優れものです。

このプラグインを使って以下の論文をピックアップしました。
- TimeGPT-1
- PromptCast: A New Prompt-based Learning Paradigm for Time Series Forecasting
- Large Language Models Are Zero-Shot Time Series Forecasters

これらの論文を読むにあたって、初めに概要をサクッと掴むためにChatPDFというサービスを活用しました。このサービスは、PDFを投げるとそのPDFを要約してくれます。さらに、本文の要点を理解するための質問作成とその回答も作成してくれます。また、以下の様なプロンプトを投げることで、理解を深めるための壁打ちができます。
LLMを時系列予測に使用する利点と、欠損データやテキスト情報の取り扱いにおける優位性は何ですか?

論文の概要
ChatPDFを使って出力した論文の概要は以下の様になります。
1.TimeGPT-1
TimeGPTは、大規模な時系列モデルであり、追加のトレーニングを必要とせずに、多様なドメインにわたって正確な予測を提供することができます。このようなモデルは、機械学習や時系列分析に関する広範な専門知識を持たないユーザーを含め、より広い範囲のユーザーに高度な予測能力を提供し、意思決定の改善につながり、重要な分野での不確実性とリスクを減らす可能性があります。また、最小限の計算複雑性で正確な予測を生成する効率性は、予測プロセスを効率化し、組織や個人の時間とリソースを節約することができます。TimeGPTのような基礎モデルの利用可能性は、時系列分析の分野でのさらなるイノベーションや探索を促し、様々なドメインでの新しいアプリケーションや洞察の開発につながる可能性があります。
従来の機械学習手法や統計的手法に対して、Zero-shotで様々な時系列データの予測ができる点が便利だと思います。データサイエンティストが苦労して作成していた特徴量作成の手間を省けるのは大きいです。論文では、様々な業界の時系列データセット(1000億以上のデータポイント!)で事前学習されています。予知保全に使用する場合は、工場うやプラントで使用される装置(プレス機、ダイカスト、マシニング 、蒸留塔 etc.)のデータでファインチューニングすれば、更に精度向上が望めます。
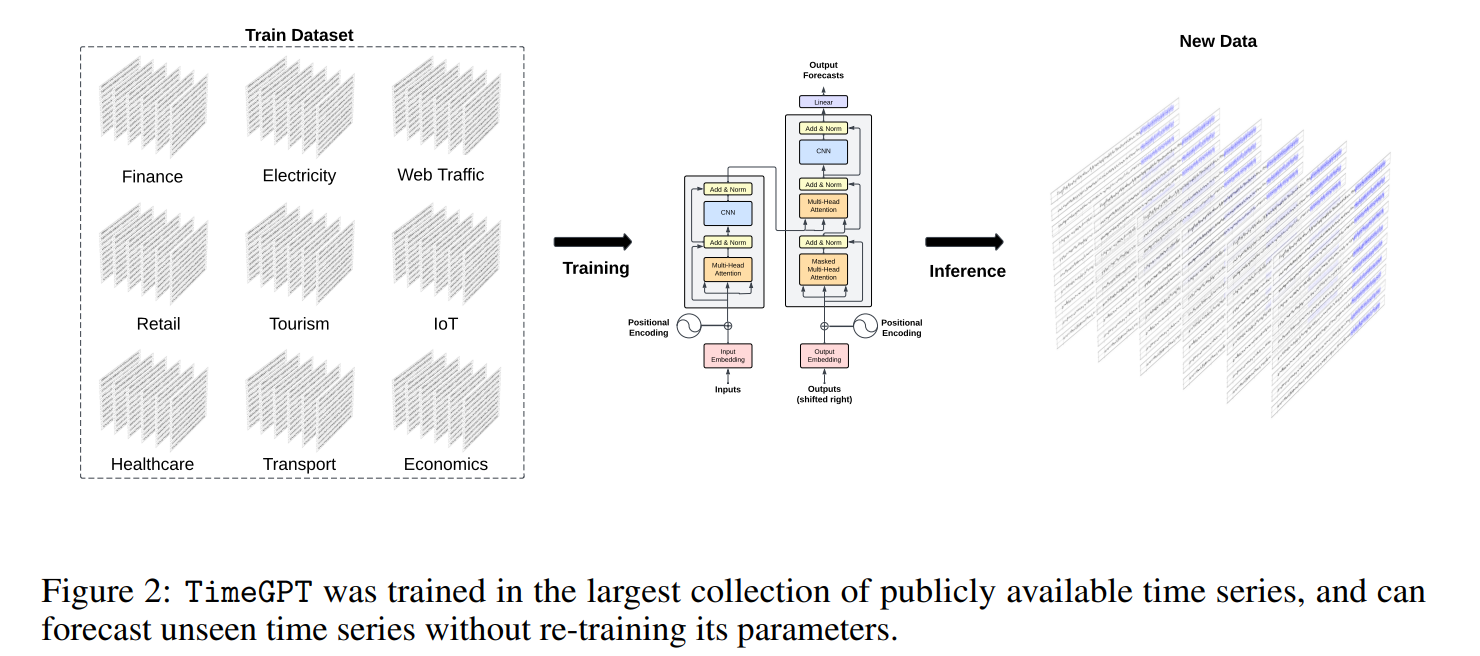
クリックで拡大
TimeGPTはBeta版が使用できるので、興味のある方は試してみると良いと思います。以下の記事が参考になります。

2.PromptCast: A New Prompt-based Learning Paradigm for Time Series Forecasting
この論文では、PromptCastという新しいタスクを提案し、言語モデルを用いた時系列予測について調査しています。言語モデルには、BART、PEGASUS、BIGBIRDの3つのモデルが使用され、数値ベースの予測モデルには、Informer、Autoformer、FEDformerの3つのモデルが使用されました。PISAデータセットを使用して、言語モデルと数値ベースの予測モデルの性能を比較しました。評価指標として、平均絶対誤差(MAE)と平均二乗誤差(MSE)を使用し、3つの異なる予測シナリオで評価を行いました。また、言語モデルの汎化能力や実世界の新しい予測シナリオにおける適用可能性を調査するために、zero-shotやTraining From Scratchといった手法を用いた実験も行われました。結果として、言語モデルを用いたPromptCastは、数値ベースの予測モデルと比較して良好な予測性能を示し、汎化能力も高いことが示されました。
この手法の特長は2つあります。
1つ目は、自然言語で訓練したモデルを、推論も自然言語(プロンプトによって)で行えることです。例えば、保全マンが「明日の1時から8時までの、ナフサクラッカーA配管の圧力センサBの値を教えて」というプロンプトを投げることで、自然言語だけで予知保全ができる可能性があります。以下の図の様に、現場のタブレットからプロンプトをChatbotに入力して、設備保全に活用できそうです。

クリックで拡大
2つ目の利点は、これまで特徴量に落とし込めなかった4M情報をモデルへ組み込める可能性があることです。この論文のモデルで使わている訓練用のプロンプト・正解文と4M情報を盛り込んだVerを提示します。
<論文Ver.>
プロンプト:
The average temperature was 54, 58, 53, 59, 56, 58, 58, 63, 57, 63, 65, 53, 46, 48, 56 degree on each day. What is the temperature going to be on tomorrow?
(各日の平均気温は54度、58度、53度、59度、56度、58度、58度、63度、57度、63度、65度、53度、46度、48度、56度だった。明日の気温は?)正解文:
The temperature will be 64 degree.
(気温は64度。)
<4M情報追加Ver.>
プロンプト:
The average sensor 2 values for naphtha cracker piping 1 were 54, 58, 53, 59, 56, 58, 63, 57, 63, 65, 53, 46, 48, 56 degree. The piping was serviced two weeks ago, during which time Mr. A was in charge of the operation. What are the values tomorrow?
(ナフサクラッカー配管1のセンサー2値の平均値は54度、58度、53度、59度、56度、58度、63度、57度、63度、65度、53度、46度、48度、56度であった。配管の整備は2週間前に行われ、その間Aさんが運転担当だった。明日の値は?)正解文:
The value will be 64 degree.
(値は64度。)
ただし、訓練用プロンプトと正解文を作るのに多大なコストがかかると思われます(;^_^A。訓練用プロンプトを時系列データから自動作成する技術も重要になります。
尚、上記論文のモデルと訓練用のプロンプト・正解文は以下から取得できます。

3.Large Language Models Are Zero-Shot Time Series Forecasters
本論文では、大規模言語モデル(LLM)を用いた時系列予測手法「LLMTIME」を提案しています。LLMTIMEは、時系列データを数値の文字列として表現し、テキストの次のトークン予測として時系列予測を行うことで、事前学習済みのLLMを活用することができます。LLMは、一般的な時系列のパターンに対するバイアスを持ち、多様な分布を表現する能力を持つため、時系列予測において高い性能を発揮することが期待されます。また、LLMTIMEは欠損データやテキスト情報の取り扱いにも優れており、追加の情報を取り入れて予測を行うことが可能です。実験により、LLMTIMEは既存の時系列予測手法に比べて高い性能を発揮することが示されています。
この手法は、LLMが過去の文章から次の単語を予測することを利用しています。つまり、時系列データを数値の文字列と捉えて、次の文字列を予測します。
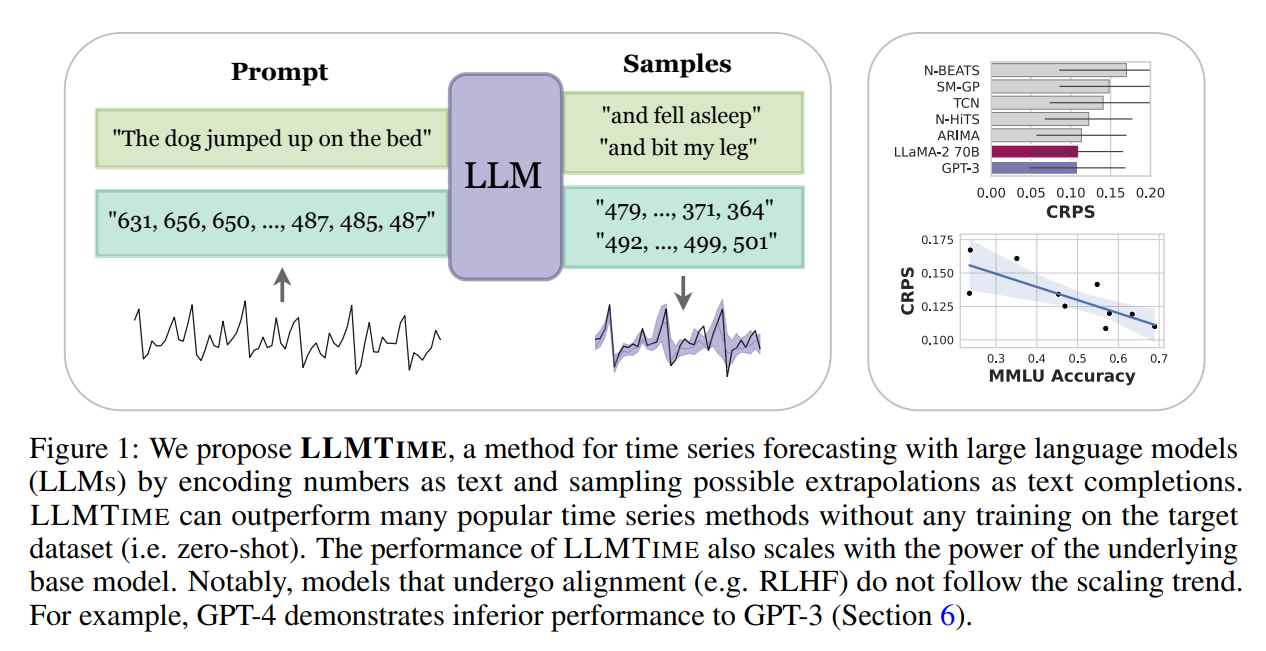
クリックで拡大
したがって、初めに時系列データ(数値)を、以下の様にトークン化する必要あります。
![]()
このトークン化の方法が予測精度に大きく影響します。時系列予測でもプロンプトエンジニアリングが重要と言うことです。下図の様に数値の間に半角スペースを入れてトークン化するか否かで予測精度が大きく変わります。しかもその傾向がGPT-3とLLaMAで逆になっています(GPT-3はスぺース追加で精度向上するが、LLaMAは低下)。
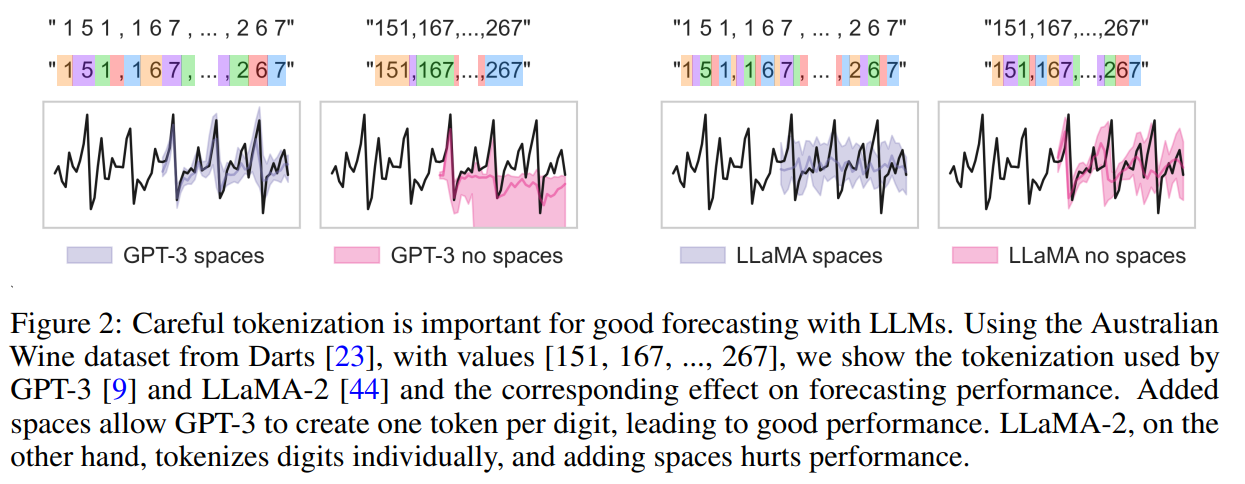
クリックで拡大
この手法の特長は高い予測精度と、高い訓練効率です。下図左上段の(みんな大好き)AirPassengersのデータセットにおいても、トレンド成分と周期成分を捉えられていることが分かります。また、中央の図から、2つ目の論文で取り上げたPromptCastよりも精度が高いことが分かります。また、右端の図から、従来の機械学習手法よりも訓練効率(トレーニングデータの割合に対する精度)で優れることが分かります。これは、トレーニングデータの割合が少ない場合でも高い予測性能を維持できることを示しています。LLMTIMEがデータを効率的に活用し、相対的にデータが少ない状況でも高い予測精度を達成できることを示唆しており、設備異常データが限られている予知保全システム開発における、LLMTIMEの有用性を示しています。
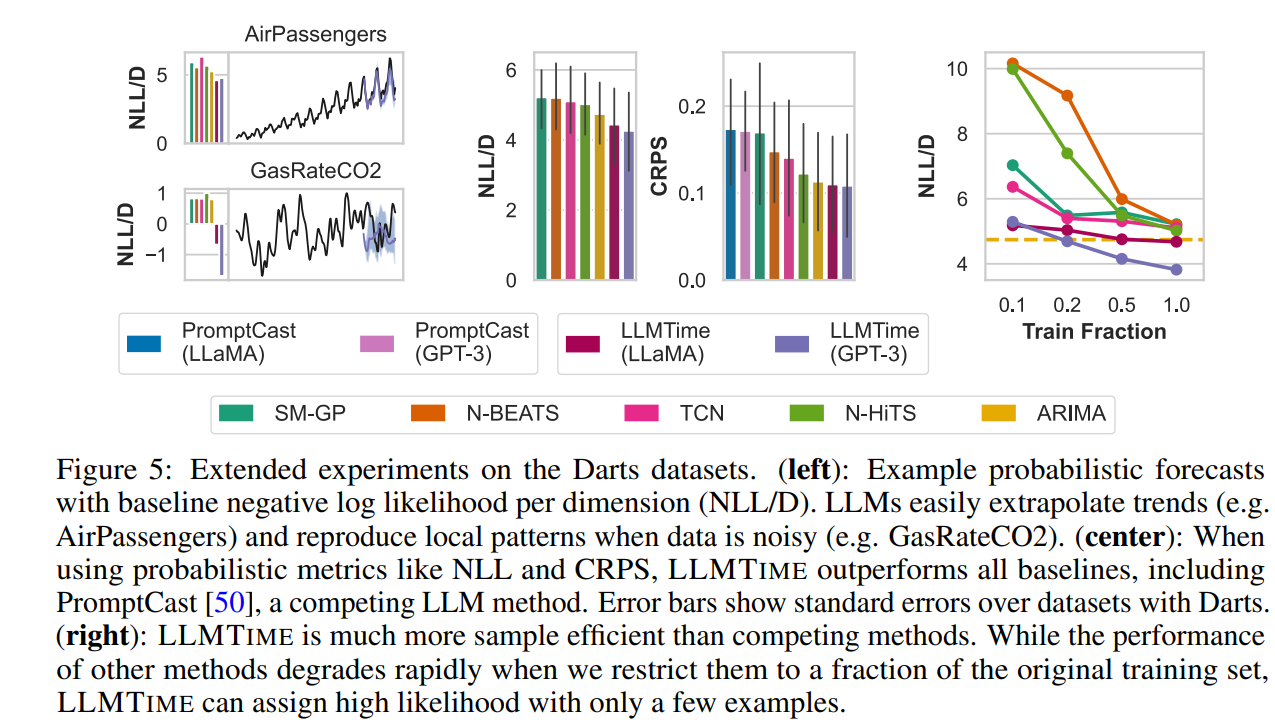
クリックで拡大
また、PromptCastよりもLLMTIMEが優れ理由をChatPDFに解説させました。
(めちゃ便利!家庭教師ですね。これは、、笑)

クリックで拡大
まとめ
今回、GPTの予知保全システムへの応用を念頭に論文を調査し、私見を述べました。以下に再度整理します。
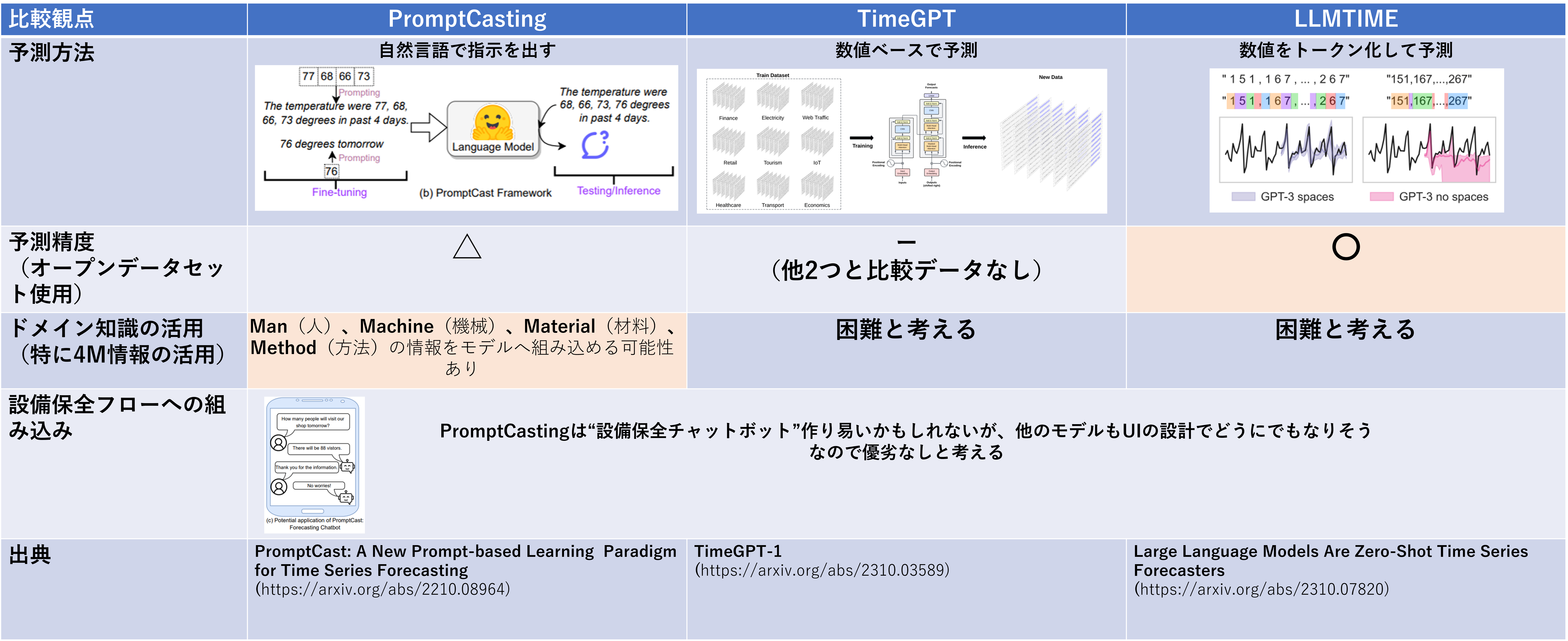
クリックで拡大
図中の〇、△は相対評価です。〇:従来の機械学習手法より優れる、△従来の機械学習手法と同等以上。
従来の機械学習モデルの置き換えという点では、TimeGPTとLLTTIMEが相性が良いと考えます。しかし、PromptCastingは製造業でのAI活用のキーとなる4M情報を盛り込める可能性があり、時系列データ×データサイエンスだけでは超えられなかった壁を越えられる可能性もあると思います。実際に、設備保全フローに組み込む際は、学習時間、推論時間、サブスクリプション費用などを鑑みた TCO(Total Cost of Ownership)で決定する必要があります。
GPTの予知保全システムへの応用はまだまだ様々な課題が多くありますが、Zero-shotで推論できることやドメイン知識を人が特徴量化せずともモデルへ組み込める可能性のあることは大きな魅力です。現状は各社、GPTの活用は社内版ChatGPTに留まると思いますが、今後製造現場へ本格的にGPTが導入されることと思います。また、時間がある時にモデルを動かして、オープンデータで検証してみたいと思います。

