
本記事の内容
はじめに
データを活用して、ビジネス価値に繋げ、さらにスケールアップさせるためには「データ基盤」が必要になります。
私はメーカーでデータサイエンティストとして働いています。業務の中で、データ基盤が無い or 整備が十分でないことにより業務効率が落ちていると感じることがあります。
データ基盤を用いたデータ連携の重要性は以前、以下のブログに書きました。良ければ、以下ご覧ください。

データ基盤がない、という企業も多いのではないでしょうか?
私自身、データ基盤の整備担当ではありませんが、今後、工場でのデータ活用を進めるにあたり、必要になる知識だと感じています。
そんな折、Twitterで話題になっている書籍がありました。
著者のゆずたそ(@yuzutas0)さんから献本いただき、読ませていただきました。
ECサイトをモデルケースにした著書ではありますが、製造現場のデータ基盤にも転用できる内容になっています。


図1:突然、任命されても慌てなくてOK!
特に大事だと感じたポイント
こちらの著書には、データ基盤作成、活用のために必要なエッセンスが詰まっています。
その全てについて取り上げることは難しく、著作権法にも抵触する可能性があるため、製造現場向けのデータ基盤として特に重要と思った点をまとめます。
ポイント
設備のデータであれば、適切なセンサ、取り付け状態が大事。
外観検査データであれば、照明を含む撮像系が大事になる。
データが生じる現場(=製造ラインと仮定)に負担を掛けないデータ取りの仕組みが大切
当たり前の話ではありますが、データ解析を始める前に業務フローをどう変えるか具体的にイメージしておく必要があります。
そのイメージがないと、的外れな評価指標を設定してしまうなど、手戻りが発生します😅
データはオンプレミスにあったとしても、データレイクはクラウドを使うのが得策と考えます。ただし、一般的にクラウドに製造データを上げることはハードルが高いため、稟議を通すための作戦が必要になります。
分析用DBには大きく分けて4つの種類があります。担当者はどのDBを選ぶべきか?、非常に参考になると思います。
次項から、私の業務上の経験を踏まえて説明します。
書籍で取り上げているポイントと外れる項目もあります。ご了承ください😀
書きすぎると、書籍のネタバレなりそうなので、特筆すべき項目に絞ります。
データ品質がやっぱり命

1-2項 データの品質は生成元のデータソースで担保する
データの品質はデータの生成元で担保すべきことが述べられています。
これは、製造データでも非常に大切です。
以前ツイートした際には、同じような課題を持っている方が多いのか、多くの「いいね」をいただきました。
https://twitter.com/industrial_ds/status/1494968393879138306

図2:設備(データ生成元) ⇒ データサイエンティストにデータが渡るまで(クリックで拡大)
しかし、「データが適切に取られているか?」を検証することは非常に難しいです。
初めに、適切なセンシング状態とは?を定義しないといけません😅
これは、現場のエキスパートではないデータサイエンティストには難しいので、
「少なくともこの状態だったら、適切にセンシングできていない(=まともなデータが取れていない)可能性が高いよね?」
ということをPJの初めに確認しておくのが現実的だと思います。
以下に、Sushi Sensorを例に代表的な確認事項をまとめました。

図3:データソースについて、最低限確認しておきたいこと(クリックで拡大)
失敗経験を踏まえて、各項目を確認する理由を述べます。
- 測定精度
データ解析、特徴量抽出した変化点が実はノイズでした💦、、とならないように。。正常/異常が層別できる特徴量が確認できたとして、「それが、本質的変化か?」を判断するのに必要な情報になります
図4:数理モデルはデータの品質を判断してくれない(クリックで拡大)

- 測定原理
どのような理由でノイズ、欠損が生じるのかを考察するために必要な情報
- 測定環境上の制約
センシングされた環境が、センサーにとって適切な環境であったかを確認しておきます。許容されている環境から外れていると、適切なデータが取れていない可能性があります。

図5:許容範囲で使用しないとデータ品質が劣化する(クリックで拡大)
- フィルタリングの有無
センサー ~ DCS、PLC間の処理で意図せずデータ加工されていることがあります。
入手したデータは生値か?その点について確認しておきます。
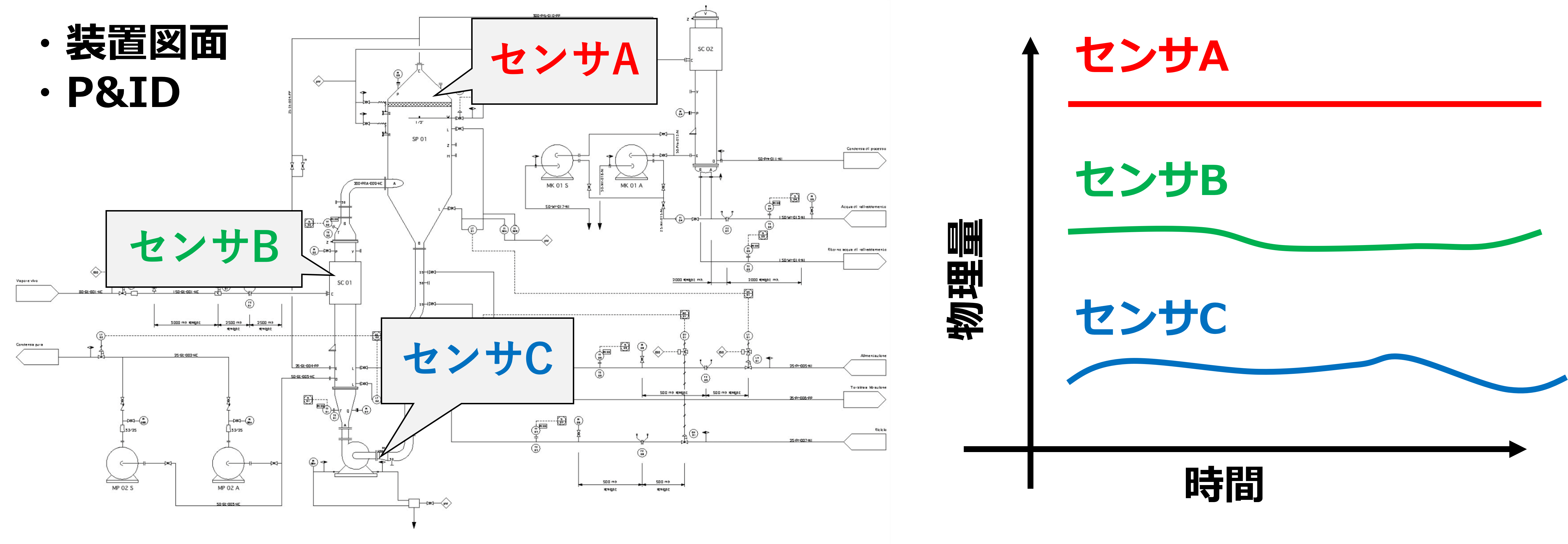
- センサー取り付け位置
最も重要な情報だと思います。同じ時系列データでも「どの位置に取り付けられたセンサーのデータか?」によって、解釈の仕方が変わってきます。
さらに、位置情報を何らかの形で機械学習の入力とすることでより高精度な解析ができると思われます。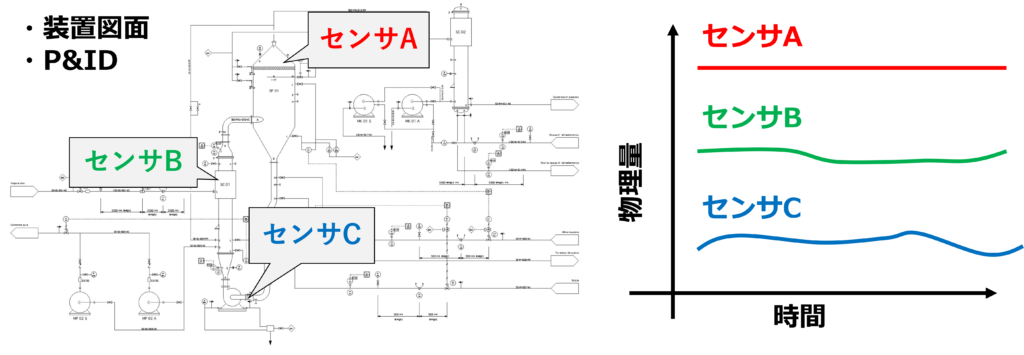
図6:センサーの位置もデータ解析の重要情報(クリックで拡大)
以上のように、工場からデータを受け取った際は、
一歩立ち止まって、「データ品質が担保されているか?」を考えると後々の手戻りを防ぐことができます。
開発者とユーザーの描く完成形を一致させる
1-9項 ユースケースを優先的に検討し、ツールの整備を逆算する
書籍の観点と少しずれますが、こちらの項目にも製造現場でデータ活用を進めるにあたって重要な示唆が書かれていました。
それは、「システム運用後の業務フローを要件定義段階で明確化しておく」ことが重要と言うことです。
システム運用後の業務フローによって、以下が変わってきます。
- どんな機械学習指標、統計量をアウトプットするべきか?
- どのタイミングでアウトプットすべきか?
- どのようなGUIにすべきか?
- どのようなドキュメントを出力すべきか?
システム開発者(データサイエンティスト、機械学習エンジニア)とユーザー(生技、製造、保全)が違うことはままあります。
その場合、お互いに描いている未来が違うと、ユーザーの要求を満たせないものが出来上がります。

図7:業務フローをどう変えたいか?(クリックで拡大)
データレイクがないと、開発が非効率になり易い

2-12項 データレイクでは収集したデータを無くさないようにする
こちらも、書籍とやや観点がずれるのですが、示唆的なことが書いてありました。
データの非連携が壁となってPJが遅延することがあります。
書籍で述べられているのは、データレイクが存在することを前提にした話ですが、データレイク自体がない工場システムも多いです。
なので、まずは図1のデータレイク層を用意したいところです。
さらに、筆者は、データレイクについて、オンプレではなくクラウド利用を推奨されています。現在、工場系システムにデータレイクがなく1から作成する場合、私もクラウド利用が良いと思います。理由は以下です。
- 従量課金で利用できるため、初期投資を抑えられる(書籍記載)
- 運用人件費が安い(書籍記載)
- 耐久性が高い(書籍記載)
- 基盤構築にかかる時間が短い(私見)
- 情報セキュリティ担保に係る社内工数が少ない(私見)
最後の2点は書籍には書かれいません。
情報セキュリティは、工場系データベースを全社サーバーに繋ぎ、一元化する際に特にケアしないといけない事柄になります。
昨今もトヨタ系サプライヤーがサイバー攻撃を受けました。日系企業への攻撃はますます増えるものと予想します。

図:デンソーへのサイバー攻撃(クリックでリンクに飛びます)
製造ノウハウが詰まっている、工場データを守るために、オンプレで固めるのではなく、情報セキュリティが強固であるクラウドを活用するのも手だと思います。
(情報セキュリティについて素人であるため、異なる意見、指摘いただけると幸いです。🙇♂️)
最後に

データサイエンスが活用できる業界は多岐に渡ります。
- 金融
- 製造
- 小売り
- 広告
- 不動産 etc.
その中で、製造業では物理量をデータとして扱うことが多いため、システム品質に直結するデータ品質には特に気を付ける必要があります。
データ品質を判断するアルゴリズム、評価指標、ノウハウの蓄積がこれからますます重要になると思われます。
