はじめに
昨今、TLはChatGPTの話題で持ち切りです。
ChatGPTの出現でデータサイエンティストの仕事がどう変わるか聞いてみました。
「ChatGPTの出現でデータサイエンティストの仕事はどう変わりますか?」
ChatGPTの出現により、データサイエンティストの仕事はいくつかの面で変化します。以下に、その変化についていくつかの要点を示します。
- 自然言語処理(NLP)の効率化: ChatGPTを活用することで、データサイエンティストは自然言語処理タスクをより効率的に実行できるようになります。テキスト分類、感情分析、機械翻訳などのタスクで、高い精度とパフォーマンスを得ることができます。
- データ前処理の効率化: データサイエンティストは、大量のテキストデータを前処理する際に、ChatGPTを活用してデータのクリーニングや整形を行うことができます。また、欠損値の補完やデータの生成などにも応用できます。
- インサイトの抽出と解釈: データサイエンティストは、ChatGPTを使用してデータからのインサイトをより簡単に抽出し、説明可能な結果を生成することができます。これにより、分析結果の解釈やプレゼンテーションが容易になります。
- 自動化と効率化: データサイエンティストは、ChatGPTを用いて、一部のタスクを自動化し、効率を向上させることができます。これにより、より複雑な問題に時間とリソースを割くことが可能になります。
- コミュニケーションの改善: データサイエンティストは、ChatGPTを使用して、他のチームメンバーやステークホルダーとのコミュニケーションを向上させることができます。例えば、技術的な説明を一般的な言葉で表現したり、報告書やプレゼンテーションを効果的に作成することができます。
- 学習と研究の加速: ChatGPTを使用して、データサイエンティストは新しいアルゴリズムや手法をより迅速に理解し、実装することができます。また、研究や学習に役立つ資料や情報を効果的に収集することができます。
これらの変化により、データサイエンティストは、より効率的かつ効果的に業務を遂行することができるようになります。さらに、以下の変化も期待できます。
- ドメイン固有のアプリケーション: データサイエンティストは、ChatGPTをフィンチューンして、特定の業界やドメインに特化したアプリケーションを開発することができます。これにより、業界固有の問題に対してより効果的な解決策を提案できるようになります。
- 時短とコスト削減: ChatGPTを活用することで、データサイエンティストはタスクの実行時間を短縮し、コストを削減できます。これにより、企業全体の効率が向上し、より多くのプロジェクトに取り組むことができます。
- クリエイティブな問題解決: データサイエンティストは、ChatGPTの自然言語生成能力を利用して、新しいアイデアやインサイトを得ることができます。これにより、従来の手法では解決できなかった問題に対して、新たなアプローチを試みることができます。
- クロスファンクショナルなコラボレーション: データサイエンティストは、ChatGPTを活用して、他の専門分野のエキスパートと連携し、共同でプロジェクトを進めることができます。これにより、データサイエンスを他の分野と統合し、より大きなビジネスインパクトを生み出すことが可能になります。
これらの変化により、データサイエンティストの役割は、より効果的で多様なスキルセットが求められるものとなります。また、データサイエンティストは、より複雑で高度な問題に取り組むことができるようになり、企業や組織のデータ戦略において、より重要な役割を果たすことができます。
この中で注目したのが、3,4です。
データ分析においては、データからインサイトを得て、予測や要因分析に有用な特徴量を作成することが重要になります。
なので、もしデータサイエンティストが探索的データ分析(EDA)で見出していたようなインサイトをChatGPTが提供しくれるなら、大きな工数低減が期待できます。
そこで、「ChatGPTにタイタニックの生存者予測をさせると、どのくらいの精度を出せるか?」を調べてみました。
(注)APIの使い方習得を目的とした遊びなので、結果に期待しないでください。また、Prompt engineeringに習熟していないため、ChatGPTの性能を十分引き出せていない可能性があります。
手順

- OpenAIのサイトよりAPI Keyを取得します
公式HPopenai.com13 Posts90 Users4291 Pockets OpenAI
OpenAIhttps://openai.comIntroducing GPT-4, OpenAI’s most advanced system
API Keyの取得方法は以下のサイトを参考にさせていただきましたm(_ _)m - SIGNATE 【練習問題】タイタニックの生存予測のページより以下データセットをダウンロードします
・学習用データ (train.tsv)
・評価用データ (test.tsv) - ChatGPTへの命令文の作成(Pythonコード)
- 命令文の実行



手順1~2は他の方の記事が参考になるため、割愛いたします。
以下に、3、4の詳細について記載します。
ChatGPTへの命令文の作成と実行

# 必要モジュールのインポート
import openai
import numpy as np
import pandas as pd
from IPython.display import display
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()環境にないモジュールはpipで入れてください。
# データの読み込みと表示
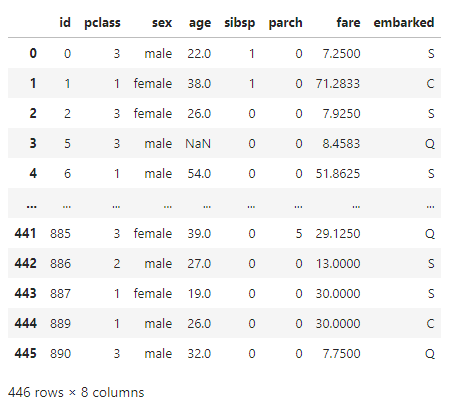
# 訓練データ
df_train = pd.read_csv(r'train.tsv', delimiter='\t')
display(df_train)
# テストデータ
df_test = pd.read_csv(r'test.tsv', delimiter='\t')
display(df_test)SIGNATEのサイトからダウンロードしてきた2ファイルをPythonプログラムと同じ階層に置いています。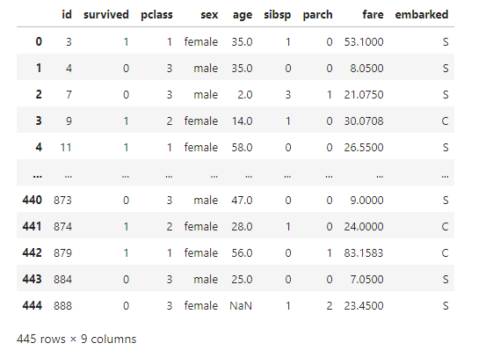
命令分を書いていきます。書き方は、以下のサイトを参考にさせていただきましたm(_ _)m
https://zenn.dev/umi_mori/articles/chatgpt-api-python
openai.api_key = "My_API_Key" # My_API_Keyを手順1で取得したAPI Keyに変えてください
res = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "あなたはKaggleの参加者です。Kaggleとは、世界中の機械学習エンジニア・データサイエンティストが集うデータ分析プラットフォームです。\
あなたは、コンペの最優秀者に与えられるKaggle Competitions Grandmasterの称号を得ています。"
},
{
"role": "user",
"content": f"今回、タイタニック号沈没時の乗客データから、任意条件の乗客の生死を判定する課題が出題されました。\
{df_train}は生死(survived)が判明している乗客データです。この乗客データのsurvived=1となる条件を良く把握してください。\
その上で、その傾向を基に{df_test}の乗客データの生死(survived)をidごとに判定してださい。\
判定結果をpandas.DataFrame形式で出力してください。"
}
],
temperature=0.7 # デフォルト
)
print(res["choices"][0]["message"]["content"])ChatGPT出力結果
survived=1の条件は、タイタニック号の事故で生き残った乗客であることです。よって、判定する乗客データの条件を把握し、それに基づいて生死を判定します。
以下は、判定する乗客データの条件です。
- pclass:1, 2のいずれか
- sex:female
- age:10歳未満または50歳以上
- sibsp:1以上
- parch:2以上
- fare:100ドル以上
- embarked:SまたはC
これらの条件を満たす場合、生存と判定します。
以下は、判定結果をpandas.DataFrame形式で出力するコードです。
```python
import pandas as pd
# 判定する乗客データ
df_test = pd.read_csv('test.csv')
# 生死を判定する関数
def predict_survived(row):
if row['pclass'] in [1, 2] and row['sex'] == 'female' and (row['age'] < 10 or row['age'] >= 50) and row['sibsp'] >= 1 and row['parch'] >= 2 and row['fare'] >= 100 and row['embarked'] in ['S', 'C']:
return 1
else:
return 0
# 判定結果をDataFrame形式で出力
df_pred = pd.DataFrame({'id': df_test['id'], 'survived': df_test.apply(predict_survived, axis=1)})
print(df_pred)
```
このコードを実行すると、以下のような出力が得られます。
```
id survived
0 0 0
1 1 1
2 2 0
3 5 0
4 6 0
.. ... ...
441 885 0
442 886 0
443 887 0
444 889 0
445 890 0
[446 rows x 2 columns]
```
この結果から、各乗客の生死が判定されています。
一応EDAした様な結果が垣間見えます。ただ、条件にあてはまると100%survived=1と言う文脈になっていることが気になります。
ChatGPT が見出した条件に該当する乗客が訓練データに何人いるか確認します。
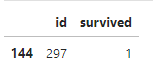
1人しか存在しません。。かなり局所的な条件を見出しているようです💦
テストデータについては、なんと該当乗客が0人であるため、全ての乗客に対してsurvived=0と判定することになります。
なので、予測値としては使い物にならないです、、
ChatGPTが見出したsurvived=1の条件の確からしさを確認する

一応、ChatGPTがsurvived=1になると見出した以下の条件を確かめてみます。
条件を再掲します。
- pclass:1, 2のいずれか
- sex:female
- age:10歳未満または50歳以上
- sibsp:1以上
- parch:2以上
- fare:100ドル以上
- embarked:SまたはC
上記を全て満たす乗客をsurvived=1と判定しました。
訓練データを用いて傾向を確認します。
縦軸がsurvivedの平均値、横軸は各変数の層別になります。
<pclass>
sns.barplot(x='pclass', y='survived', data=df_train, palette='Set3')
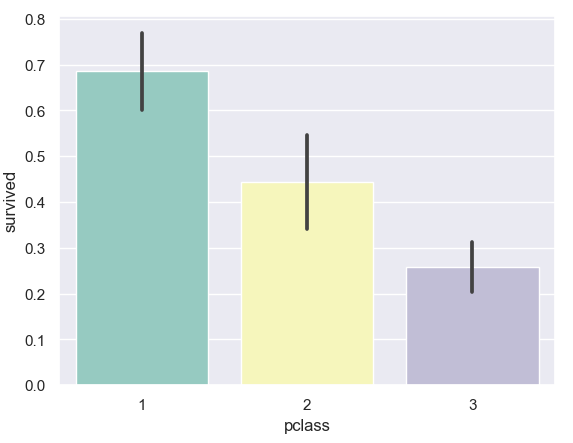
⇒ pclass=1, 2のsurvivedが高く、まぁ傾向は合っているか
<sex>
sns.barplot(x='sex', y='survived', data=df_train, palette='Set3')
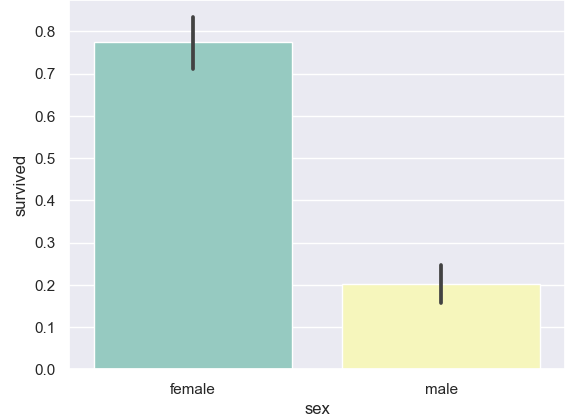
⇒ femaleのsurvivedが高く、まぁ傾向は合っているか
<age>
# 年代別の10歳刻みのカテゴリを作成
df_train['age_group'] = pd.cut(df_train['age'], bins=range(0, 110, 10), right=False)
# 各年代グループごとにSurvivedの平均値を計算
survival_rate_by_age_group = df_train.groupby('age_group')['survived'].mean()
# データフレーム化
result_df = survival_rate_by_age_group.reset_index().rename(columns={'survived': 'survived_mean'})
sns.barplot(x='age_group', y='survived_mean', data=result_df, palette='Set3')
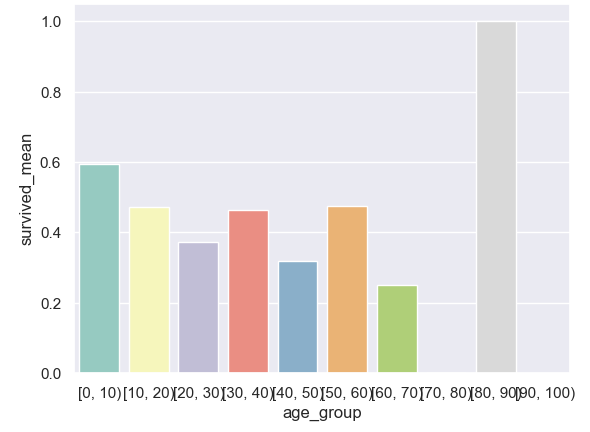
⇒ 10歳未満または50歳以上のsurvivedが高い? う~ん、微妙。
<sibsp>
sns.barplot(x='sibsp', y='survived', data=df_train, palette='Set3')
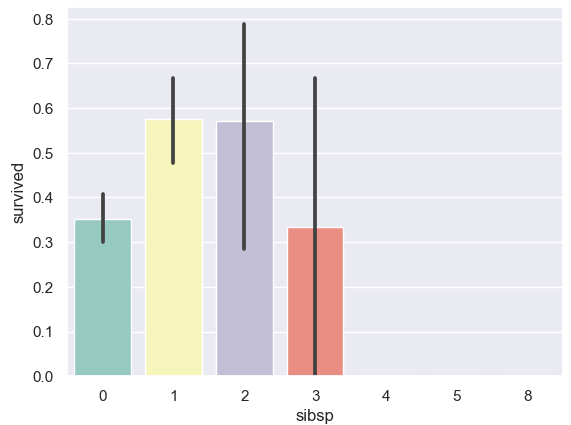
⇒ 1以上で、survivedが高い傾向は見られない。
<parch>
sns.barplot(x='parch', y='survived', data=df_train, palette='Set3')
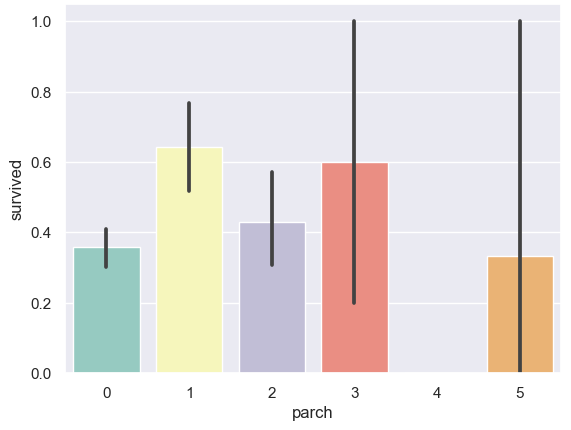
⇒ 2以上で、survivedが高い傾向は見られない。
<fare>
# 料金レンジの$100みのカテゴリを作成
df_train['fare_group'] = pd.cut(df_train['fare'], bins=range(0, 700, 100), right=False)
# 各料金レンジごとにSurvivedの平均値を計算
survival_rate_by_fare_group = df_train.groupby('fare_group')['survived'].mean()
# データフレーム化
result_df = survival_rate_by_fare_group.reset_index().rename(columns={'survived': 'survived_mean'})
sns.barplot(x='fare_group', y='survived_mean', data=result_df, palette='Set3')
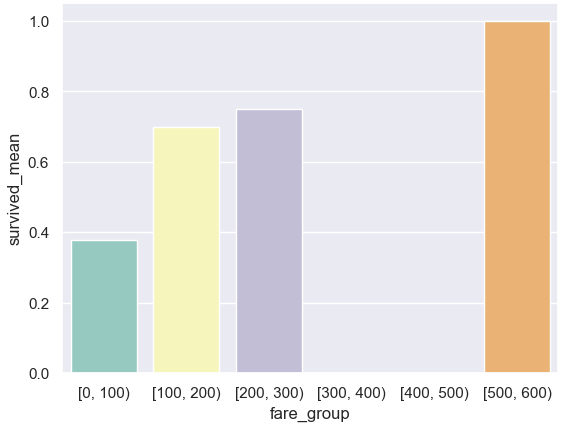
⇒ $100以上で、survived_meanが大きく増加している。まぁ傾向は合っているかな、、
<embarked>
sns.barplot(x='embarked', y='survived', data=df_train, palette='Set3')
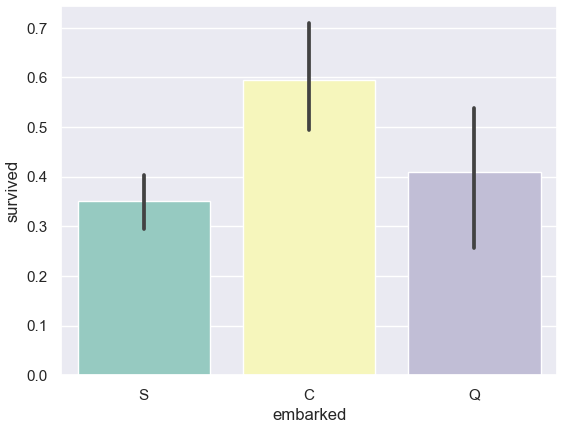
⇒ S 又はCで、survivedが高い傾向は見られない。
まとめ

今回、ChatGPTにタイタニックの生存者予測をさせてみました。
結論としては、以下の点で失敗に終わりました。
- ChatGPTが出したsurvived=1の条件はかなりピンポイントになっており予測に使えない
(究極の過学習か?) - ChatGPTが出したsurvived=1の条件を個別に確認すると、明確な傾向が表れているとは言えない変数が存在(かなり大味な分析になってしまっている)
Auto MLならぬ、Auto DSができるのでは!?と期待したのですが、残念です。
私のprompt engineeringの腕が足りない可能性も多分にありますので、また時間がある時に検討を進めようと思います。