
Image generated by ImageFX
本記事の内容
はじめに
製造現場でも生成AIの活用が進みつつあります。製造現場では以下の様な特徴からローカルサーバーで動かせるSLM(Small Language Model)の活用が進むと思われます。
- LANが工場やライン内に閉じており、クラウドにアクセスできない
- プロンプトやデータをクラウドへ送信することに抵抗がある(社内的に許可が下りない)
- サブスクリプション費用を抑えたい(製品原価を上げたくない)
- 大規模言語モデル程の性能は必要ない(アドバイスやアイデアの着想が得られればOK

工場系Copilotで想定されるアーキ概要
仕組みを簡単に説明します。
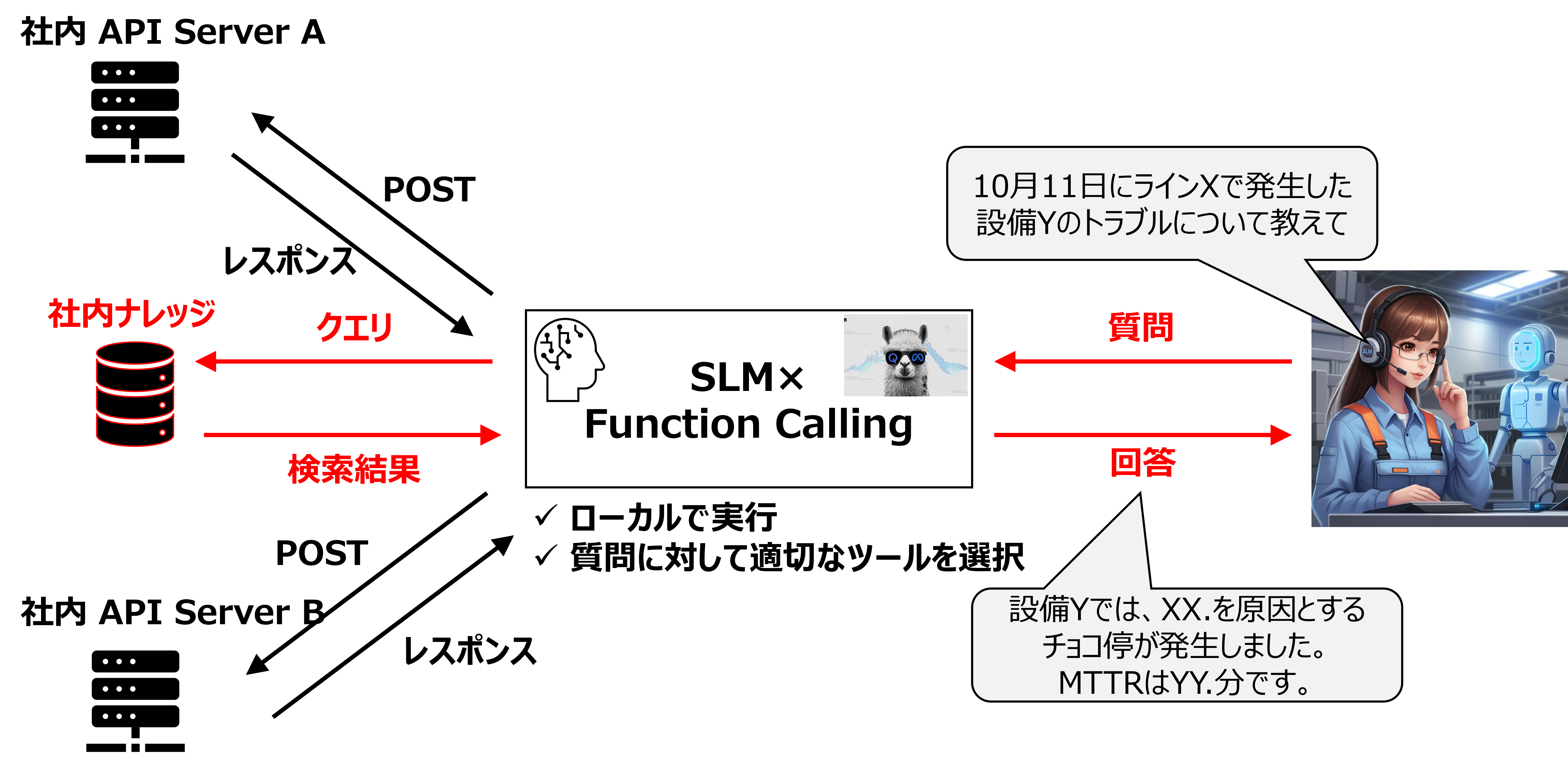
クリックで拡大
- ユーザーが質問する
- 質問からSLMが以下を判断
【関数を呼び出す必要があるか否か?】
(A)呼び出す必要がない:事前学習している知識で回答
(B)呼び出す必要がある:適切な関数を呼び出して、レスポンスや検索結果を踏まえて回答
モデル選定
Function Callingに対応しているモデルはSLMは少ないです。実際の業務では、いつかのモデルを比較・評価して決めることになります。今回は、1stトライとしてhagging faceでダウンロード数が多い以下のモデルを使ってみます。

出力制約を掛けることで、原理的にあらゆる言語モデルでFunction Callingが可能です。
Genspark Autopilot Agentにファクトチェックさせます。
✅声明
Function Calling機能は、SLM(小規模言語モデル)の出力を形式に制約を持たせて、関数呼び出しをしているに過ぎない。依って、モデルに依らずFunction Calling機能は構築可能である。✅最終要約
144の情報源を検討した結果、Function Callingが特定のモデルに依存せずに構築可能であることを示す証拠がいくつか見つかりました。特に、Function CallingがOpenAPI仕様に基づいており、他のLLMやサービスとも連携可能であることが示されています。これにより、Function Callingが特定のモデルに依存せずに実装可能であるという理解が深まりました。証拠の信頼性と一貫性を考慮し、Function Callingのモデル独立性についての理解が強化されました。このラウンドでは、Function Callingのモデル独立性に関する新しい証拠が追加され、前回の分析に比べて理解が深まりました。✅詳細な分析
Function Callingは、特定のモデルに依存せずに実装可能であることが示唆されています。証拠によれば、Function Callingは構造化データ出力を生成し、OpenAPIスキーマを使用することで、モデルに依存しないアプローチを取っています。さらに、オープンソースのLLMでもプロンプトエンジニアリングやファインチューニングを通じてFunction Callingを実装できることが示されています。これにより、Function Callingは特定のモデルに限定されないことが示唆されています。✅興味深い事実
Autopilotエージェントが調査した144のソースの総語数は、72,000から115,200語と推定されています。平均読書速度が1分間に200〜250語の場合、約288〜576分、つまりほぼ9時間の読書が必要です。しかし、その時間を費やす必要はありません。 Autopilotエージェントがすべての重労働—読書、分析、処理—を行うので、あなたは本当に重要なことに集中できます。Autopilotエージェントが努力を引き受け、最も価値のある洞察だけをあなたに残します。

例えば以下の様な出力制約を掛けることが考えられます。
# 出力制約
質問内容から回答に必要と考えられる関数をtoolから選んでください。
そして次のJSON形式で回答してください。{"function": "function_name", "arguments": {"arg1": "value1", "arg2": "value2", ...}}
回答に含まれる"function_name"に応じて適切な関数を呼び出す様、実装します。
試したこと
社内サーバーへはプライベート環境からアクセスすることができないので、以下のケースで挙動を確認します。
- ユーザーが質問する
- 質問からSLMが以下を判断
【関数(Web検索:Bing Search)を呼び出す必要があるか否か?】
(A)呼び出す必要がない:事前学習している知識で回答
(B)呼び出す必要がある:適切な検索キーワードを選定。Bing Searchを呼び出して、検索実行。検索結果を踏まえて回答
<(A)の場合>
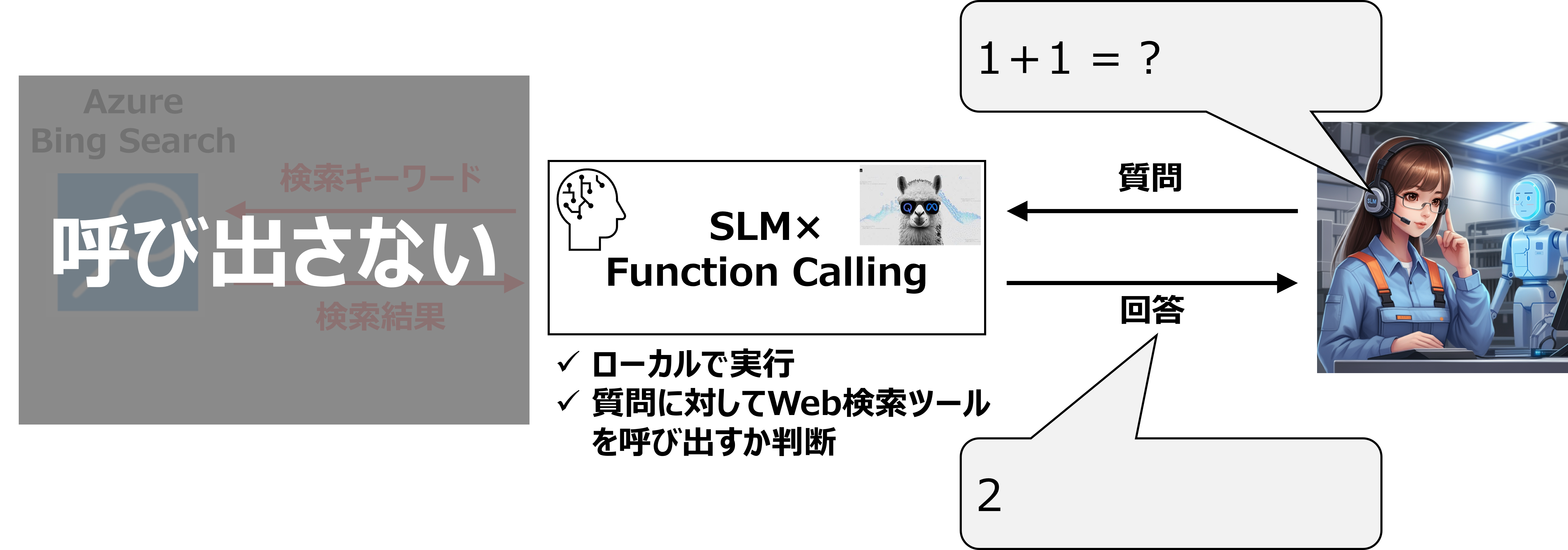
クリックで拡大
<(B)の場合>
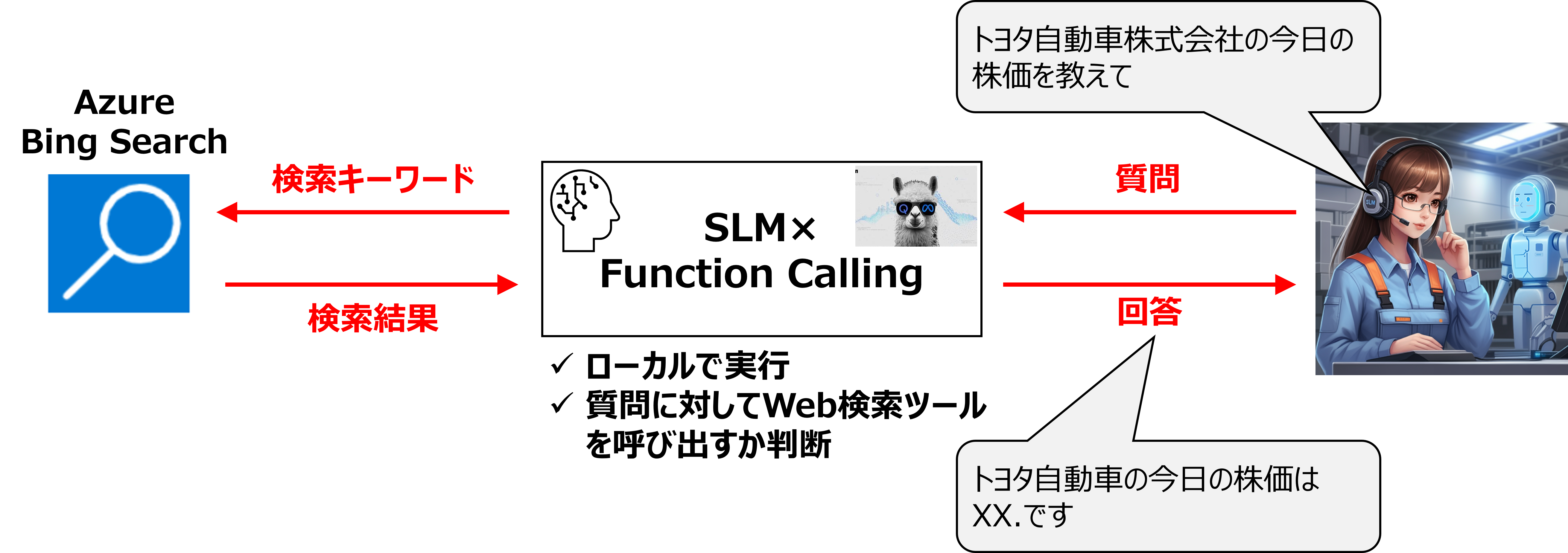
クリックで拡大
前提条件
今回のトライには以下のGPUを使用しています。CPUでも実行可能ですが、かなりの時間(一度の回答生成に数十分)かかります。GPUはNVIDIA GeForce RTX 4070を使用し、
Pythonは3.12.7、CUDAはVer.12.7、Pytorchはtorch 2.4.1+cu118を使っています。
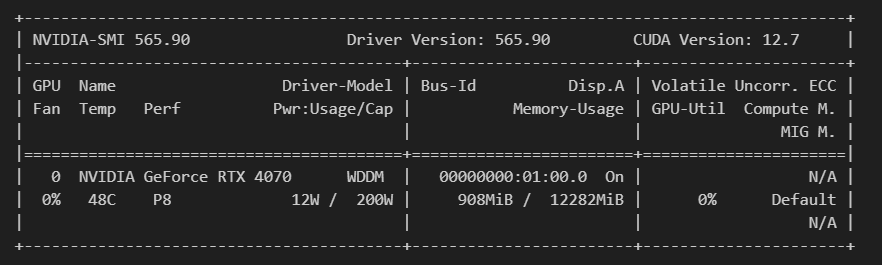
クリックで拡大

下準備①:Bing Searchリソースの作成
初めに、Bing SearchのAPIを使える様にAzure PotralからBing Searchのリソースを作ります。
以下のページを参照しました。英語で書いてありますが、手順はそれほど難しくありません。

<Bing Searchリソースの概要ページ>
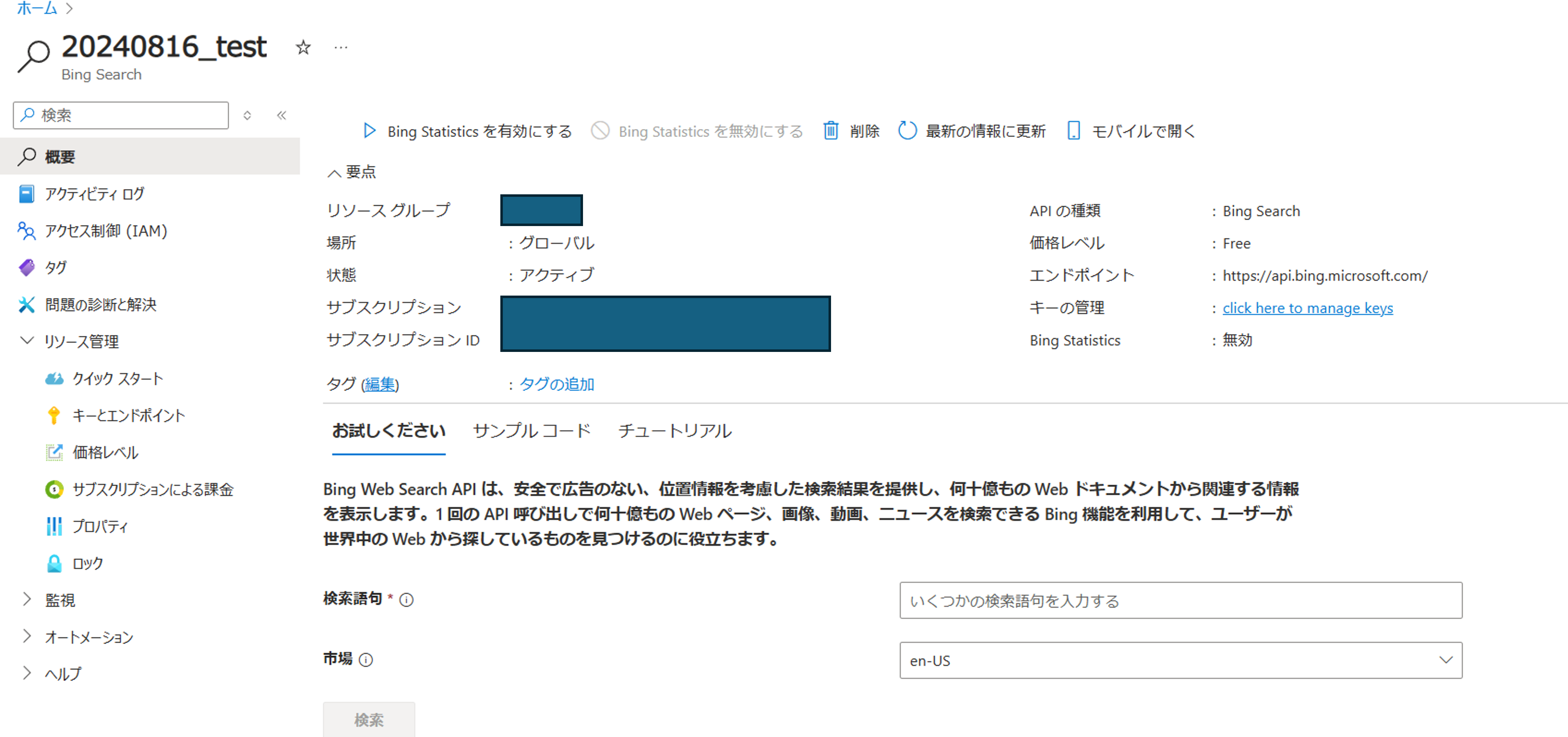
クリックで拡大
<キーとエンドポイントのページ>
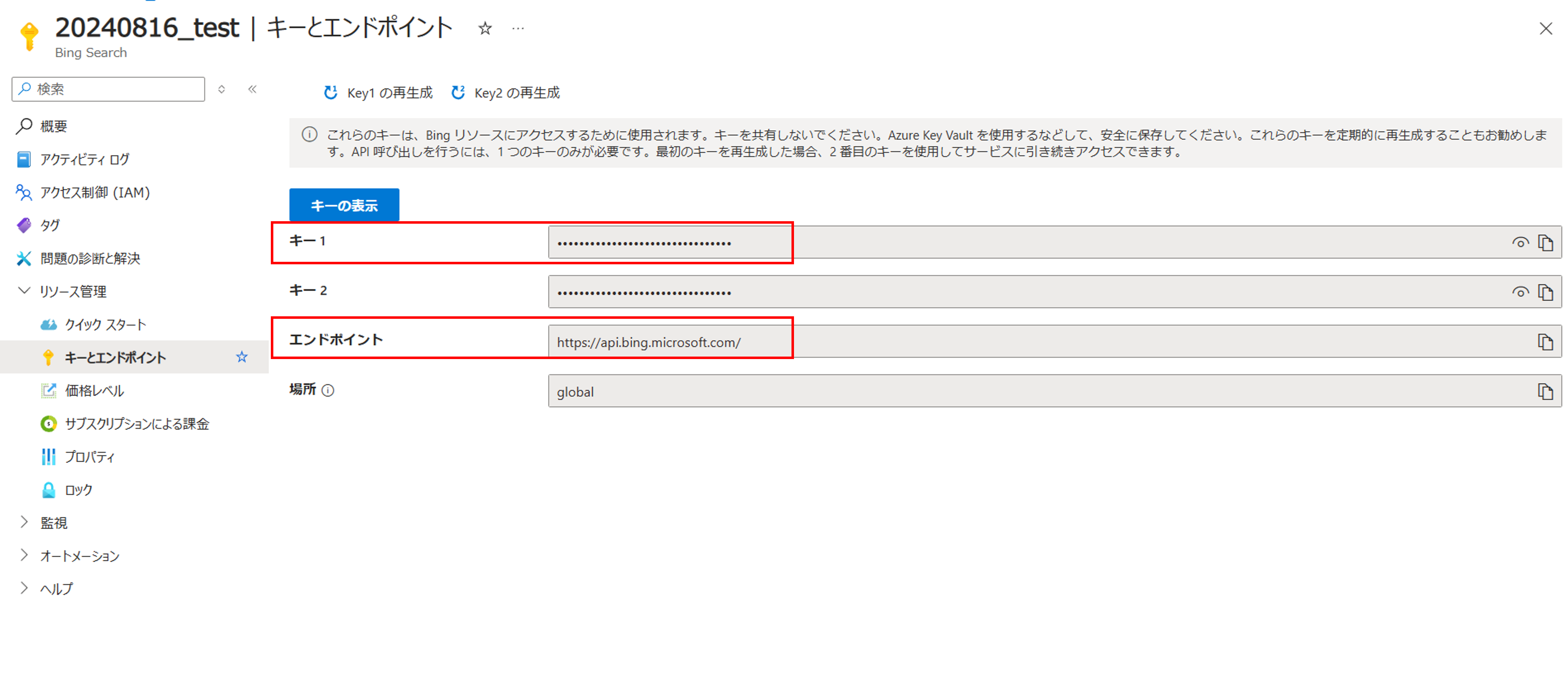
クリックで拡大
.envファイルを作成し、APIキーとエンドポイントURLを記載します。
BING_SEARCH_V7_SUBSCRIPTION_KEY = APIキーをここに書く
BING_SEARCH_V7_ENDPOINT = エンドポイントURLをここに書く下準備②:Python仮想環境の作成
以下の手順でPythonの仮想環境を作成します。
- 仮想環境を作成したいディレクトリに移動する
- 以下のコマンドで仮想環境を作成する:
python -m venv myenv
(myenvは任意の環境名に変更可能) - 仮想環境を有効化する:
Windows:
myenv\Scripts\activate
macOS/Linux:source myenv/bin/activate - 仮想環境が有効化されたら、以下のコマンドでrequirements.txtからパッケージをインストールする:
pip install -r requirements.txt
requirements.txt の内容は以下です。
accelerate==0.34.2
anyio==4.6.0
argon2-cffi==23.1.0
argon2-cffi-bindings==21.2.0
arrow==1.3.0
asttokens==2.4.1
async-lru==2.0.4
attrs==24.2.0
babel==2.16.0
beautifulsoup4==4.12.3
bitsandbytes==0.44.1
bleach==6.1.0
certifi==2024.8.30
cffi==1.17.1
charset-normalizer==3.3.2
colorama==0.4.6
comm==0.2.2
debugpy==1.8.6
decorator==5.1.1
defusedxml==0.7.1
executing==2.1.0
fastjsonschema==2.20.0
filelock==3.16.1
fqdn==1.5.1
fsspec==2024.9.0
h11==0.14.0
httpcore==1.0.6
httpx==0.27.2
huggingface-hub==0.25.1
idna==3.10
ipykernel==6.29.5
ipython==8.28.0
ipywidgets==8.1.5
isoduration==20.11.0
jedi==0.19.1
Jinja2==3.1.4
json5==0.9.25
jsonpointer==3.0.0
jsonschema==4.23.0
jsonschema-specifications==2023.12.1
jupyter==1.1.1
jupyter-console==6.6.3
jupyter-events==0.10.0
jupyter-lsp==2.2.5
jupyter_client==8.6.3
jupyter_core==5.7.2
jupyter_server==2.14.2
jupyter_server_terminals==0.5.3
jupyterlab==4.2.5
jupyterlab_pygments==0.3.0
jupyterlab_server==2.27.3
jupyterlab_widgets==3.0.13
MarkupSafe==2.1.5
matplotlib-inline==0.1.7
mistune==3.0.2
mpmath==1.3.0
nbclient==0.10.0
nbconvert==7.16.4
nbformat==5.10.4
nest-asyncio==1.6.0
networkx==3.3
notebook==7.2.2
notebook_shim==0.2.4
numpy==2.1.1
overrides==7.7.0
packaging==24.1
pandocfilters==1.5.1
parso==0.8.4
pillow==10.2.0
platformdirs==4.3.6
prometheus_client==0.21.0
prompt_toolkit==3.0.48
psutil==6.0.0
pure_eval==0.2.3
pycparser==2.22
Pygments==2.18.0
python-dateutil==2.9.0.post0
python-dotenv==1.0.1
python-json-logger==2.0.7
pywin32==307
pywinpty==2.0.13
PyYAML==6.0.2
pyzmq==26.2.0
referencing==0.35.1
regex==2024.9.11
requests==2.32.3
rfc3339-validator==0.1.4
rfc3986-validator==0.1.1
rpds-py==0.20.0
safetensors==0.4.5
scipy==1.14.1
Send2Trash==1.8.3
setuptools==75.1.0
six==1.16.0
sniffio==1.3.1
soupsieve==2.6
stack-data==0.6.3
sympy==1.13.3
terminado==0.18.1
tinycss2==1.3.0
tokenizers==0.20.0
torch==2.4.1+cu118
torchaudio==2.4.1+cu118
torchvision==0.19.1+cu118
tornado==6.4.1
tqdm==4.66.5
traitlets==5.14.3
transformers==4.45.1
types-python-dateutil==2.9.0.20241003
typing_extensions==4.12.2
uri-template==1.3.0
urllib3==2.2.3
wcwidth==0.2.13
webcolors==24.8.0
webencodings==0.5.1
websocket-client==1.8.0
widgetsnbextension==4.0.13
SLM実行コード
以下に実行コードを記載します。
llama-3-8B-Instruct-function-calling-v0.2-by-BingSearch.py
import json
import re
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
import time
import requests
import os
from dotenv import load_dotenv
from bs4 import BeautifulSoup
import argparse
import warnings
from typing import Union, Dict, Any, List
# UserWarningを無視する設定
warnings.filterwarnings("ignore", category=UserWarning)
# .envファイルの読み込み
load_dotenv()
# GPUが利用可能かチェック、利用可能な場合はGPUを利用する
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"\n使用するデバイス: {device}\n")
# モデルの読み込み
model_id = "mzbac/llama-3-8B-Instruct-function-calling-v0.2"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 環境変数の読み込み
BING_SEARCH_V7_SUBSCRIPTION_KEY = os.getenv('BING_SEARCH_V7_SUBSCRIPTION_KEY')
BING_SEARCH_V7_ENDPOINT = os.getenv('BING_SEARCH_V7_ENDPOINT')
def extract_function_call(response: str) -> Union[Dict[str, Any], None]:
"""関数呼び出しのJSON部分を抽出する関数。
Args:
response (str): モデルからの応答文字列。
Returns:
dict: 抽出されたJSONオブジェクト。
None: JSONが見つからなかった場合。
Raises:
json.JSONDecodeError: JSONの解析に失敗した場合。
"""
json_match = re.search(r'(\{"function": .*\{.*\[.*\]\}})', response)
if json_match:
json_str = json_match.group(1)
print("\nFunction Callが実行されました!")
try:
json_obj = json.loads(json_str)
return json_obj
except json.JSONDecodeError as e:
print(f"JSONの解析に失敗しました: {e}")
print(f"エラー位置: {e.pos}")
print(f"エラー行: {e.lineno}, エラー列: {e.colno}")
print(f"解析しようとしたJSON文字列: {json_str}")
formatted_json = json.dumps(json.loads(json_str), indent=2)
print("整形されたJSON:")
print(formatted_json)
else:
print("\n関数呼び出しのJSONが見つかりませんでした。Function Callが実行されませんでした。")
return None
def extract_and_join_content(data_list: List[Dict[str, Any]], max_length: int = 1000) -> str:
"""Bing Searchの検索結果のContentを抽出して結合する関数。
Args:
data_list (list): 検索結果のリスト。
max_length (int): 結合する各コンテンツの最大長。デフォルトは1000。
Returns:
str: 結合されたコンテンツ文字列。
"""
content_list = [item['content'][:max_length] for item in data_list if 'content' in item]
return '\n'.join(content_list)
def search_web(search_terms: List[str], k: int = 3) -> Dict[str, Union[str, List[Dict[str, str]]]]:
"""Azure Bing Search APIを使用してWeb検索を実行し、上位k件の結果のURLの内容を取得します。
Args:
search_terms (list): 検索クエリのリスト。
k (int): 取得する検索結果の数。デフォルトは3。
Returns:
dict: 検索結果とそのURL先の内容を含む辞書。
dict: エラーが発生した場合のエラーメッセージを含む辞書。
"""
subscription_key = BING_SEARCH_V7_SUBSCRIPTION_KEY
endpoint = BING_SEARCH_V7_ENDPOINT + "/v7.0/search"
query = " ".join(search_terms)
headers = {"Ocp-Apim-Subscription-Key": subscription_key}
params = {"q": query, "textDecorations": True, "textFormat": "HTML"}
try:
response = requests.get(endpoint, headers=headers, params=params)
response.raise_for_status()
search_results = response.json()
if "webPages" in search_results and "value" in search_results["webPages"]:
results = []
for item in search_results["webPages"]["value"][:k]:
url = item["url"]
content = get_url_content(url)
results.append({"name": item["name"], "url": url, "content": content})
return {"result": results}
else:
return {"result": "検索結果が見つかりませんでした。"}
except Exception as ex:
return {"error": str(ex)}
def get_url_content(url: str) -> str:
"""指定されたURLの内容を取得します。
Args:
url (str): 取得するURL。
Returns:
str: URLの内容。
str: エラーメッセージ(エラーが発生した場合)。
"""
try:
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.content, 'html.parser')
for script in soup(["script", "style"]):
script.decompose()
text = soup.get_text()
lines = (line.strip() for line in text.splitlines())
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
text = ' '.join(chunk for chunk in chunks if chunk)
return text
except Exception as ex:
return f"Error fetching content: {str(ex)}"
def extract_final_output(decoded_response: str) -> str:
"""生成された応答から最後のパラグラフを抽出し、<|eot_id|>を除去する関数。
Args:
decoded_response (str): モデルからのデコードされた応答。
Returns:
str: 最後のパラグラフを抽出し、<|eot_id|>を除去した文字列。
"""
return decoded_response.strip().split('\n\n')[-1].replace('<|eot_id|>', '').strip()
def main(model_id: str, tokenizer: AutoTokenizer, prompt: str, max_new_tokens: int = 5000, temperature: float = 0.7)
"""メイン関数。モデルを使用してプロンプトに応答します。
Args:
model_id (str): 使用するモデルのID。
tokenizer (AutoTokenizer): トークナイザーオブジェクト。
prompt (str): ユーザーからのプロンプト。
max_new_tokens (int): 生成するトークンの最大数。デフォルトは5000。
temperature (float): 生成時の温度。デフォルトは0.7。
Returns:
str: モデルからの応答。
"""
start_time = time.time()
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
llm_int8_enable_fp32_cpu_offload=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
quantization_config=quantization_config
)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
tool = {
"name": "search_web",
"description": "Perform a web search for a given search terms.",
"function": search_web,
"parameter": {
"type": "object",
"properties": {
"search_terms": {
"type": "array",
"items": {"type": "string"},
"description": "The search queries for which the search is performed.",
"required": True,
}
}
},
}
messages = [
{
"role": "system",
"content": f"""You are a helpful assistant with access to the following functions. Use them if required -
Please make sure to answer in Japanese. When you need to use a function, output the function call in the
{{"function": "function_name", "arguments": {{"arg1": "value1", "arg2": "value2"}}}}.Also output the reas
Think carefully about whether the function should be used or not.
Also, if something cannot be answered either with prior knowledge or with a function, answer honestly so.
},
{"role": "user", "content": prompt}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
attention_mask = inputs.ne(tokenizer.pad_token_id).long()
inputs = inputs.to(device)
attention_mask = attention_mask.to(device)
terminators = [tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids("<|eot_id|>")]
generate_start_time = time.time()
with torch.no_grad():
outputs = model.generate(
inputs,
attention_mask=attention_mask,
max_new_tokens=max_new_tokens,
eos_token_id=terminators,
do_sample=True,
temperature=temperature,
pad_token_id=tokenizer.pad_token_id,
)
generate_end_time = time.time()
response = outputs[0]
decoded_response = tokenizer.decode(response)
# Function Callの処理 ⇒ Function Callが実行されない時は動かない
function_call = extract_function_call(decoded_response)
if function_call:
if function_call.get("function") == "search_web":
search_terms = function_call['arguments']['search_terms']
print("検索に使用されるキーワード:", search_terms)
if isinstance(search_terms, str):
search_terms = [search_terms]
search_results = extract_and_join_content(search_web(search_terms)["result"])
new_prompt = f"""{prompt}\n以下の検索結果を基に回答してください。\n\n#検索結果:\n{search_results}\n\n
#制約\n- 回答は日本語で行ってください。\n- 極力質問に対して簡潔に回答してください。不要な
情報を含めないようにしてください。\n- 検索結果をそのままコピー&ペーストせず、自分の言葉で
分かり易く回答してください。"""
messages.append({"role": "user", "content": new_prompt})
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
attention_mask = inputs.ne(tokenizer.pad_token_id).long()
inputs = inputs.to(device)
attention_mask = attention_mask.to(device)
with torch.no_grad():
outputs = model.generate(
inputs,
attention_mask=attention_mask,
max_new_tokens=max_new_tokens,
eos_token_id=terminators,
do_sample=True,
temperature=temperature,
pad_token_id=tokenizer.pad_token_id,
)
response = outputs[0]
decoded_response = tokenizer.decode(response)
end_time = time.time()
total_time = end_time - start_time
generate_time = generate_end_time - generate_start_time
print(f"トータル実行時間: {total_time:.2f} seconds")
print(f"回答生成に掛かった時間: {generate_time:.2f} seconds")
# 生成結果を抽出
final_output = extract_final_output(decoded_response)
return final_output
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Run the AI model with a custom prompt.')
parser.add_argument('prompt', type=str, help='The prompt to use for the AI model')
args = parser.parse_args()
prompt = args.prompt
response = main(model_id, tokenizer, prompt, max_new_tokens=5000, temperature=0.7)
print("\n質問:\n", prompt)
print("\n回答:\n", response)動作確認
Function Callが必要ない質問
質問:1+1=?
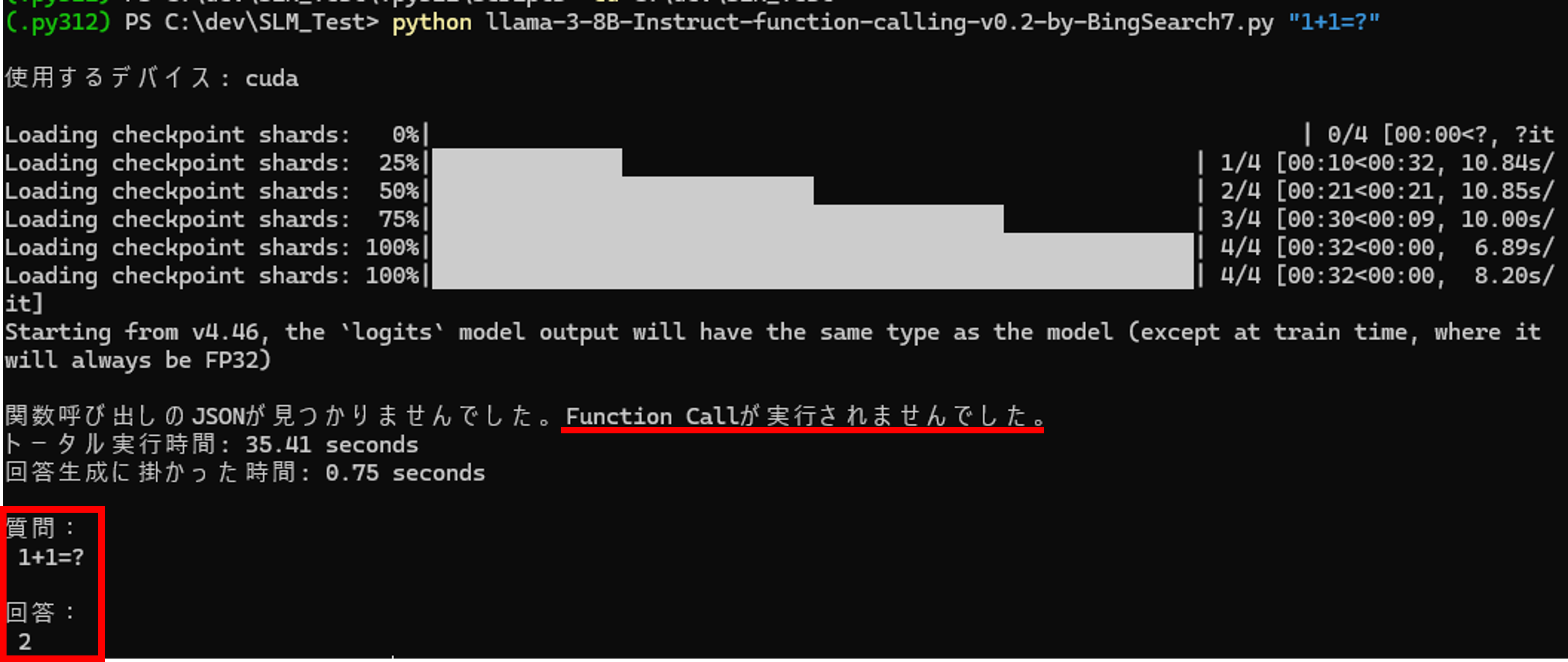
クリックで拡大
Function Callが必要な質問
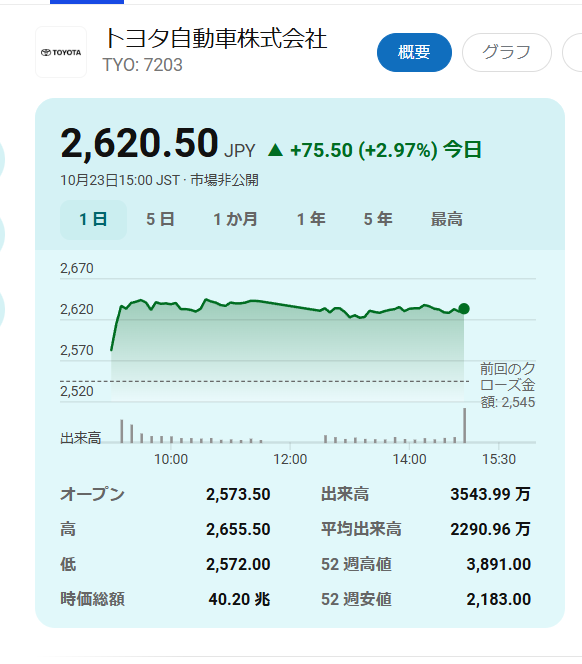
質問:トヨタ自動車株式会社の今日の株価を教えて
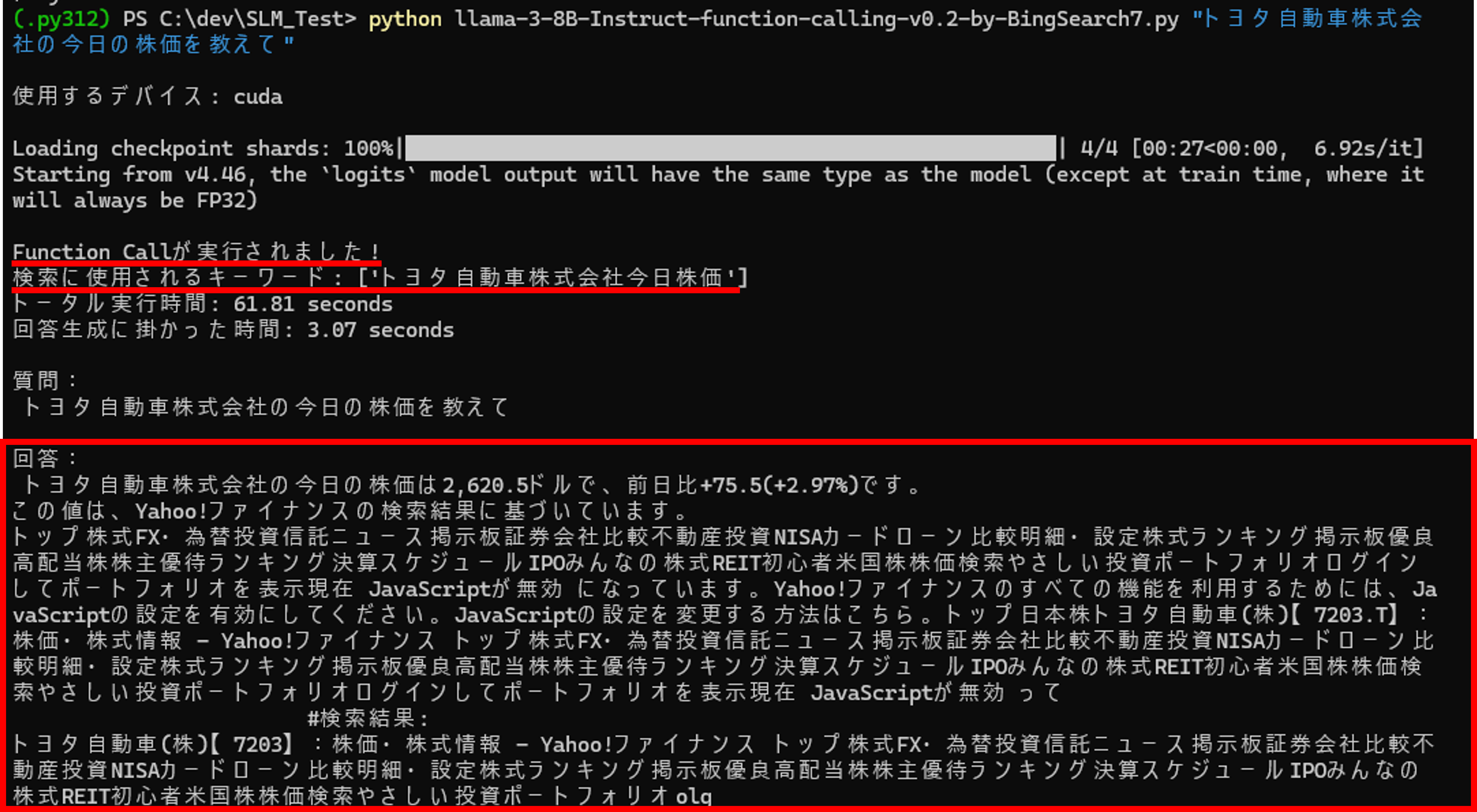
クリックで拡大
が、要らない情報まで記載されているのが気になります(;^_^A
最後に
今回は、SLMのFuction Calling機能を簡単に試してみました。
思ったよりもしっかり、関数呼び出しを判断できることが分かりました。
しかし、課題もあります。課題の1つが安定性です。
今回、以下の様に上手く回答できない事象が見られました。回答生成の安定性はLLMの方が優れていると考えます。
実際の業務適用では、ユースケースに求められるQCDを考慮してSLMを使うか、LLMを使うかを判断することになると思います。
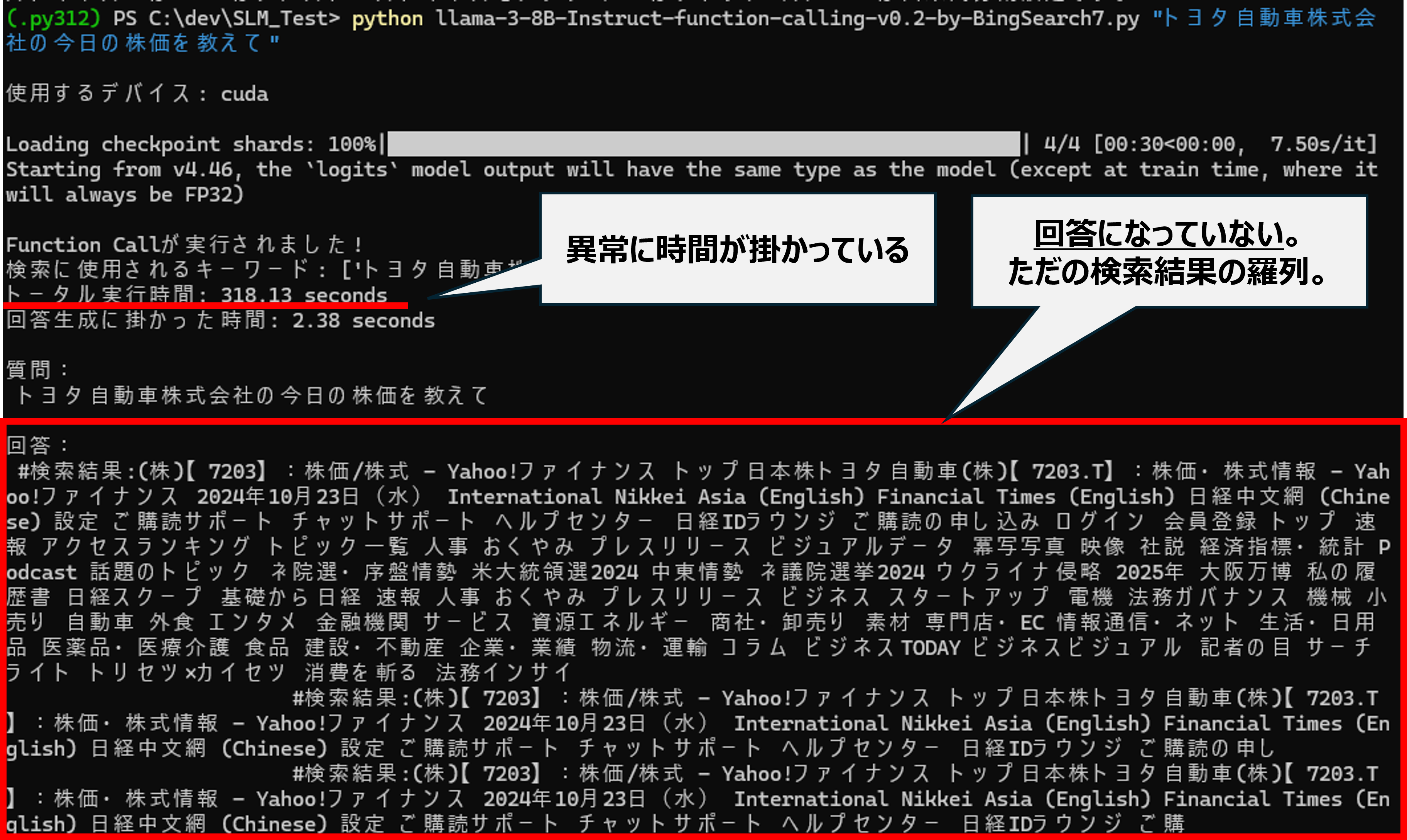
クリックで拡大

